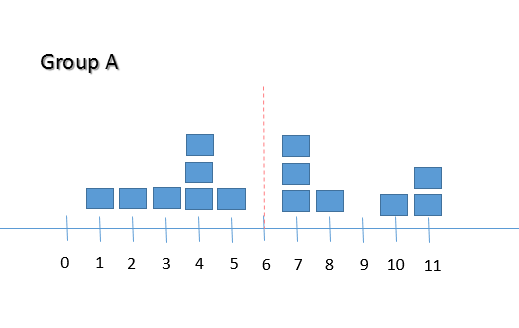
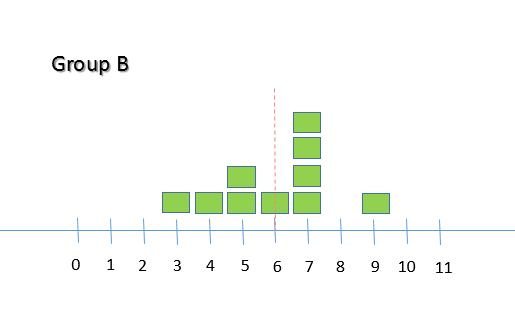
Dispersion of samples in a data set
If the samples of a data set are grouped close to the mean, the variance and standard deviation values will be close to 0. For example, consider some test scores from two groups of students: Group A = { 1, 2, 3, 4, 4, 4, 5, 7, 7, 7, 8, 10, 11, 11 } Group B = { 3, 4, 5, 5, 6, 7, 7, 7, 7, 9 } The mean score for the two groups is the same (6), but the standard deviation of each group shows SD (Group A) = 3.23 SD (Group B) = 1.76 that the samples are spread around the mean value differently. The standard deviation of Group B is closer to 0 than that of Group A so the samples of the Group B will be closer to the mean value than in Group A as shown below: